
티스토리 뷰
내용의 출처는 인프런 - 조범희님의 확률과 통계 기초 강의입니다.
1. Hyper Geometric distribution
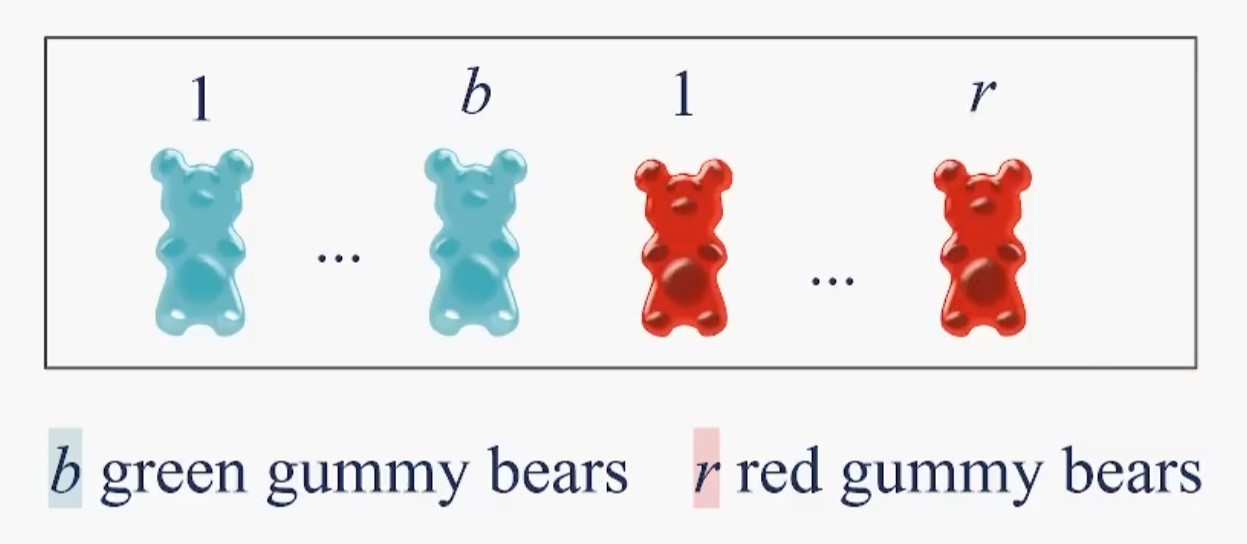
: n개의 젤리를 랜덤하게, w/o replacement로 골랐을 때 Random Variable X = blue 젤리가 선택된 수
X ~ HyperGeometric(b, r, n)
예를 들어보자, n = 5, b = 2, r = 3 이라고 하자
이때 n = 5인 모든 발생 가능한 사건의 수는 b+rC5, b=2 r=3일때 발생 가능한 모든 사건의 수는 bC2 * rC3이다.
따라서 HyperGeometric(2, 3, 5) = bC2 * rC3 / b+rC5
이것을 일반화하면 b+r에서, n개를 w/o replacement로 선택할 때
{X = i} : i개의 blue, n-i개의 red를 고르는 경우의 PMF는 PX(i) = bCi * rCn-i / b+rCn 이다.
단, max(0, n-r) ≤ i ≤ min(n, b)이다.
예제를 다시 들어보면
100개의 보석중 90개는 진품, 10개는 가품이다. 20개를 랜덤하게 비복원 추출하였을 때, 2개가 가품일 확률은?
X ~ HyperGeometric(90, 10, 20) = 90C18 * 10C2 / 100C20
2. Poisson distribution 포아송 분포
: 어디에 적용하는가? 무엇이 필요한가? 두 가지를 먼저 생각해야한다.
- 발생확률이 낮은 사건이지만 발생 가능한 경우의 수는 무궁무진한 경우
- 최소한 사건의 평균적인 발생 확률은 알고 있어야 한다.
쉽게 이해가 안간다. 예를 들어 이런 것들이 있다.
- 책의 오타 : 오타의 종류는 무궁무진하지만 막상 발생빈도는 높지 않다.
- 3일동안의 자동차 사고 건수 : 발생 가능성은 무한히 많지만, 발생 빈도는 높지 않다.
- 맥도날드 햄버거에서 머리카락 발견 수 : 발생 가능성은 무한히 많지만, 발생 빈도는 높지 않다.
- 아이패드가 일주일 내로 n대가 고장날 사건 : 발생 가능성은 무한히 많지만, 발생 빈도는 높지 않다.
포아송은 "내가 관심 있는 기간" 동안의 "사건 발생 횟수"를 Random Variable로 설정한다.
이때, "사건의 평균적인 발생 빈도"는 반드시 알아야 한다. 또한 각 사건의 발생은 독립이거나 거의 독립에 가까워야 한다. X ~ Poisson(λ) 이때 PMF는 다음과 같다.
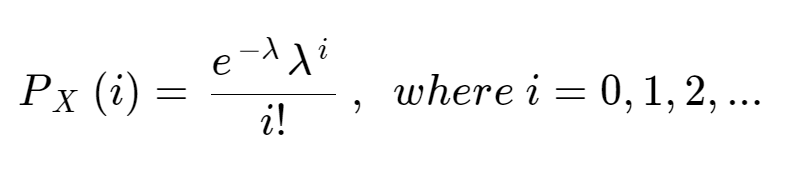
이때 λ는 평균 발생 빈도 x 관심 있는 구간으로 설정한다. 이해가 안가겠지만 예시를 들어보면 이해가 될 것이다.
ex1) 햄버거집에 3일간 50명이 올 확률, 단 하루 동안 평균적인 방문 빈도는 15명이다.
이때 λ는 평균 발생 빈도(15명) x 관심 있는 구간(3일)이므로 45이다. 관심있는 확률은 50명이 올 확률이므로
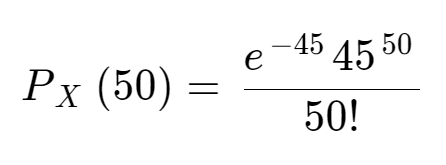
ex2) 각 페이지의 오타 발생 확률이 0.005이고 각 오타는 독립적이며 책은 총 400페이지가 있다.
a) 오직 하나의 페이지에서만 오타가 발생할 확률은?
: 재미있는 사실이 있다. a문제는 Binomial distribution으로도 풀 수 있다.
p = 0.005, n = 400일 때 X = 1의 발생 확률은 다음과 같다. X~Binomial(400, 0.005), PX(1) = 400C1(0.005)1(1-0.005)399
알겠지만, 상당히 계산하기 번거롭다. 손으로는 일단 불가능하고, 컴퓨터로도 0.995의 399승을 계산하려면 계산기에 따라 오류가 나는 경우도 있을 것이다.
반면 이 문제를 포아송 분포에 따른 확률로 계산해보자.
이때 λ는 평균 발생 빈도(0.005) x 관심 있는 구간(400페이지) = 2이다. 이때 X ~ Poisson(2), P_X(1)은 다음과 같다.
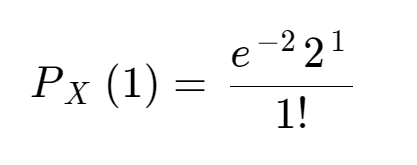
실제로 계산해보면 알겠지만, 포아송 분포로 계산한 경우와 Binomial distribution에 의해 계산한 두 경우가 아주 유사한 값을 가진다. 그리고 포아송 분포는 심지어 손으로도 계산할 수 있을만큼 간단해졌다.
즉, 포아송 분포는 계산이 번거로운 Binomial distribution을 매우 간단한 형태로 Approximation해준다.
'Background > Statistics' 카테고리의 다른 글
| Geometric distribution/ Pascal distribution (0) | 2023.07.06 |
|---|---|
| Bayesian Decision Theory 공부 정리(1) - 이해에 필요한 배경지식 (1) | 2023.04.21 |
| 1부) 베이즈 통계학 기초 -4.'확률의 확률'을 사용하여 추정의 폭을 넓힌다. (0) | 2023.03.30 |
| 1부) 베이즈 통계학 기초 -3.주관적인 숫자여도 추정이 가능하다. [발렌타인데이 초콜렛 문제] (0) | 2023.03.30 |
| 1부) 베이즈 통계학 기초 -2.베이즈 추정은 때로는 직감과 완전히 다른 결과를 보인다. (0) | 2023.03.29 |
- Total
- Today
- Yesterday
- eigenvector
- elementry matrix
- ai신약개발
- 선형대수
- 파이썬
- kl divergence
- 기계학습
- variational autoencoder
- 베이즈정리
- 제한볼츠만머신
- 인공지능
- 이왜안
- Matrix algebra
- MorganCircularfingerprint
- 3B1B따라잡기
- manimtutorial
- Manimlibrary
- 나노바디
- nanobody
- marginal likelihood
- manim
- kld
- 오일석기계학습
- 백준
- 최대우도추정
- MatrixAlgebra
- manim library
- MLE
- eigenvalue
- 3b1b
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |